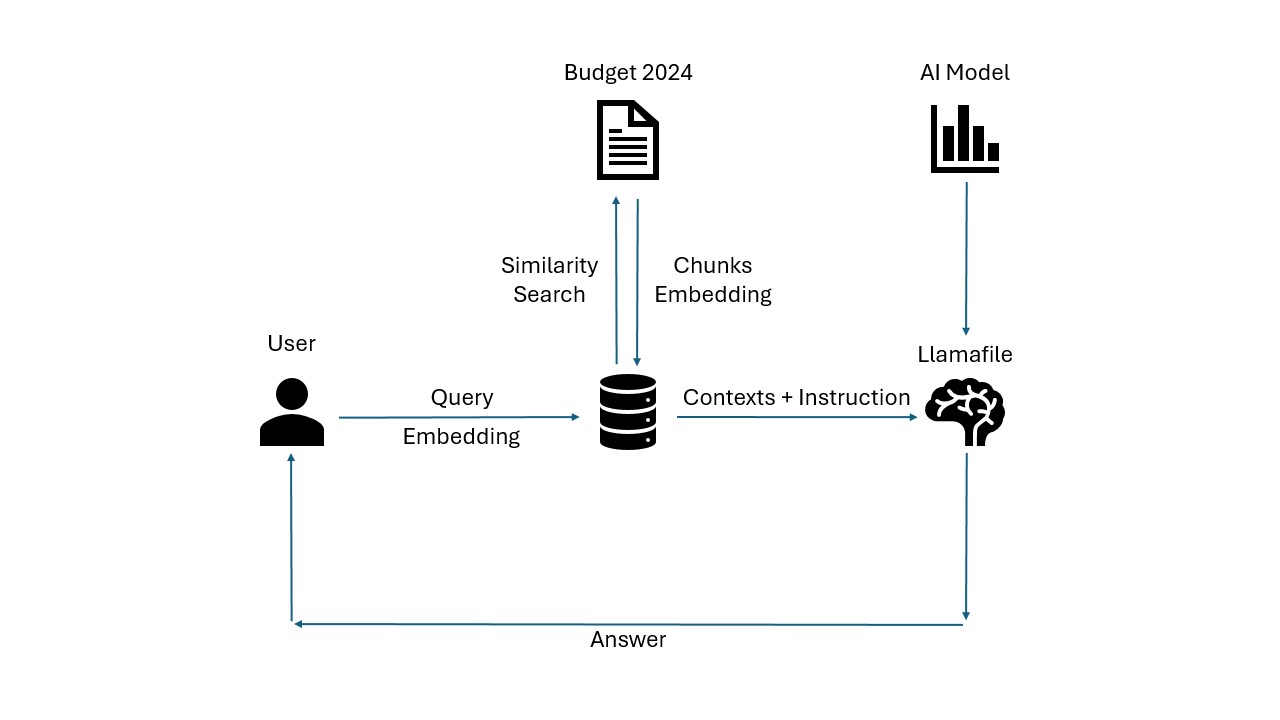
4. Building the Custom Chatbot
4.1. Load the Document
First create a document loader to load documents from a folder.
The following loader is not necessary for this tutorial but it is worthwhile to see how one can load multiple documents at once.
import os
from docx2txt import docx2txt
class SimpleDirectoryLoader(object):
def __init__(self, directory, allowed_extensions=None):
self.directory = directory
self.allowed_extensions = allowed_extensions
self.handlers = {
'.docx': self.handle_docx,
}
self.data = []
def load_files(self):
for filename in os.listdir(self.directory):
ext = os.path.splitext(filename)[-1]
if (self.allowed_extensions is None or ext in self.allowed_extensions) and ext in self.handlers:
self.handlers[ext](filename)
elif self.allowed_extensions is not None and ext not in self.allowed_extensions:
# print(f"Skipping {filename} with extension {ext}")
pass
else:
print(f"No handler for {ext} files")
return self.data
def handle_docx(self, filename):
text = docx2txt.process(os.path.join(self.directory, filename))
self.data.append({'filename': filename, 'extension': '.docx', 'data': text})
# Usage
allowed_extensions = ['.docx']
budget_loader = SimpleDirectoryLoader('path/to/your/docs/directory', allowed_extensions=allowed_extensions)
budget_doc = budget_loader.load_files()
# Print first 100 chars of the document
print(budget_doc[0]['data'][:100])
4.2. Chunk the Docs
A document can contain hundreds of pages each having thousands of words.
If we feed the bot with all of our document contents in one shot, we are definitely going to
hit the maximum input context length. Hence we need to create a list of smaller chunks from the document.
We create a chunk class to implement chunks by fixing total number of words in a chunk along with overlap.
Note: Overlapping is not neccessary but sufficient to provide relevant chunks when the context gets split between more than one chunk.
import re
from typing import List, Dict
class ChunkManager(object):
def __init__(self, docs: List[Dict[str, str]]):
self.combined_text = self._combine_texts(docs)
def _combine_texts(self, docs: List[Dict[str, str]]) -> str:
combined_text = ' '.join(doc['data'] for doc in docs)
return re.sub(r'\n+', ' ', combined_text)
def chunk_by_words_with_overlap(self, chunk_size: int, overlap: int) -> List[str]:
words = self.combined_text.split()
chunks = []
step = chunk_size - overlap
if overlap < 0:
raise ValueError("Overlap must be a non-negative integer.")
if step <= 0:
raise ValueError("Overlap must be smaller than chunk size.")
for i in range(0, len(words), step):
chunk = ' '.join(words[i:i + chunk_size])
chunks.append(chunk)
return chunks
# Usage
chunk_size = 250
overlap = 100
chunks = ChunkManager(docs=budget_doc).chunk_by_words_with_overlap(chunk_size, overlap)
print(chunks)
4.3. Create Embeddings and save in a Vector Store
Embedding is the numerical representation of the data which makes it easier for algorithms to understand and analyze the relationships between different pieces of information.
It converts the data into fixed-size of vectors. After that we can use various search algorithm like cosine similarity to find the relevant data.
In this tutorial, we use TF-IDF embeddings from scikit-learn library, and
FAISS, a cpu intesive vector storage from Facebook Research, for storing the vectors.
Note: One can use any open source embedding models (from Hugging Face) or API (Gemini, OpenAI etc.) which are dense embedding models.
We have used sparse embedding from TF-IDF.
import os
import faiss
import pickle
from sklearn.feature_extraction.text import TfidfVectorizer
class FAISS(object):
def __init__(self, max_features=768):
self.vectorizer = TfidfVectorizer(max_features=max_features)
self.index = None
self.texts = []
# Create Embeddings
def fit(self, texts):
self.texts = texts
embeddings = self.vectorizer.fit_transform(texts).toarray().astype('float32')
dimension = embeddings.shape[1]
self.index = faiss.IndexFlatL2(dimension)
self.index.add(embeddings)
return embeddings
# Function for Similarity Search through Context and Query
# Futher we fetch top k similar documents based on the query
def search(self, query, k=10):
query_embedding = self.vectorizer.transform([query]).toarray().astype('float32')
distances, indices = self.index.search(query_embedding, k)
similar_texts = [self.texts[idx] for idx in indices[0]]
return similar_texts
def save(self, dir_path, index_name='faiss'):
os.makedirs(dir_path, exist_ok=True)
with open(os.path.join(dir_path, f'{index_name}.pkl'), 'wb') as f:
pickle.dump({'vectorizer': self.vectorizer, 'texts': self.texts}, f)
faiss.write_index(self.index, os.path.join(dir_path, f'{index_name}.index'))
def load(self, dir_path, index_name='faiss'):
with open(os.path.join(dir_path, f'{index_name}.pkl'), 'rb') as f:
data = pickle.load(f)
self.vectorizer = data['vectorizer']
self.texts = data['texts']
self.index = faiss.read_index(os.path.join(dir_path, f'{index_name}.index'))
# Usage
faiss_index = FAISS()
faiss_index.fit(chunks)
# Save the embeddings for future use
faiss_index.save('path/to/your/embeddings/directory', index_name='budget_embeddings')
# Load the Budget Index
budget_index = FAISS()
budget_index.load('path/to/your/embeddings/directory', index_name='budget_embeddings')
4.4. Similarity Search
We search through the embeddings using FAISS' in-built similarity search function.
# Query the Budget Index for similar documents
query = "Who represented the Budget 2024?"
no_of_docs_to_fetch = 10 # Get top 10 similar documents
context_chunks = budget_index.search(query, k=no_of_docs_to_fetch)
print(context_chunks)
4.5. Prompt Engineering
Before we proceed to the chatting part, we need to specify the model with an instruction on how the bot will behave.
This is very important because we have seen that the quality of the response heavily depends on the framing of this prompt.
Essentially, our prompt will have 3 parts: Instruction, Context and the Query.
prompt = """You are an expert in the analysis of Government Budgets.
The following comtexts will be from India's Budget 2024.
The user will ask questions about the Budget 2024 and you have to provide the answers based on the context.
Answer in a professional tone and use bullets and paragraphs to make the answer more readable.
If you can't find the answer in the context, reply with "I am sorry, I couldn't find the answer to your question.".
Don't put any external information in the answer.
Context: {context}
Question: {question}
Answer: Your answer goes here.
"""
# Construct the prompt
prompt = prompt.format(context=context_chunks, question=query)
4.6. Run Llamafile on CPU
We have to start the Llamafile as a server through terminal.
# Make the downloaded Llamafile executable
$ chmod +x tiny.llamafile
# Launch Llamafile as a server
$ ./tiny.llamafile --nobrowser --server --port 8080 -c 4096
# This will load the model and start the server in the terminal
$ llama server listening at http://127.0.0.1:8080
4.7. Chat with the Budget Bot
Now we can chat with our custom budget bot using the prompt we have created.
import requests
class ChatLlamaFile(object):
def __init__(self, host="localhost", port=8080):
self.host = host
self.port = port
self.base_url = f"http://{host}:{port}"
self.chat_url = f"{self.base_url}/v1/chat/completions"
self.headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer no-key'
}
def chat(self, prompt, query):
data = {
"messages": [
{
"role": "system",
"content": prompt
},
{
"role": "user",
"content": query
}
]
}
response = requests.post(self.chat_url, headers=self.headers, json=data)
return response.json()
# Let's Chat
response = ChatLlamaFile().chat(prompt, query)
answer = response.get('choices')[0].get('message').get('content')
print("Query:", query)
print("Answer:", answer)
Example response:
Query: Who represented the Budget 2024?
Answer: The Budget 2024 was presented by Finance Minister Nirmala Sitharaman.